
When Less Really Is More: Privacy and A/B Testing
A companion post to the Conductrics blog post.
I'll be upfront: Conductrics is a sponsor of the TLC. But this isn't a sponsored post. It's me reading a paper by Matt Gershoff and thinking…someone needs to explain this in human terms. Because the ideas are genuinely good, like really, really good, and they deserve a wider audience than people who read academic journals for fun. (Who are you people, anyway?! Have you considered the outdoors? Or maybe a good book?)
(Matt, if you're reading this: I say that with love. You know we love you. But you write sometimes like your readers are grading dissertations… )
So here's my attempt at a translation.
The Risk Problem (few) People Talk About
We talk a lotin this community about statistical significance (what is the appropriate level, should we use 1-tailed vs 2, omg - should we even be considering sig at all - what about power instead???), Bayes vs Freq, or how about Sequential - Group Sequential…., and which method is the best for reducing variance. (🙄) We actually argue quite a lot. About a lot.
What we talk about less: most A/B testing programs are collecting way more personal data than they actually need. And that data is sitting in databases, getting shared across systems, and occasionally (sometimes very publicly) leaking in ways that can cause real harm to real people.
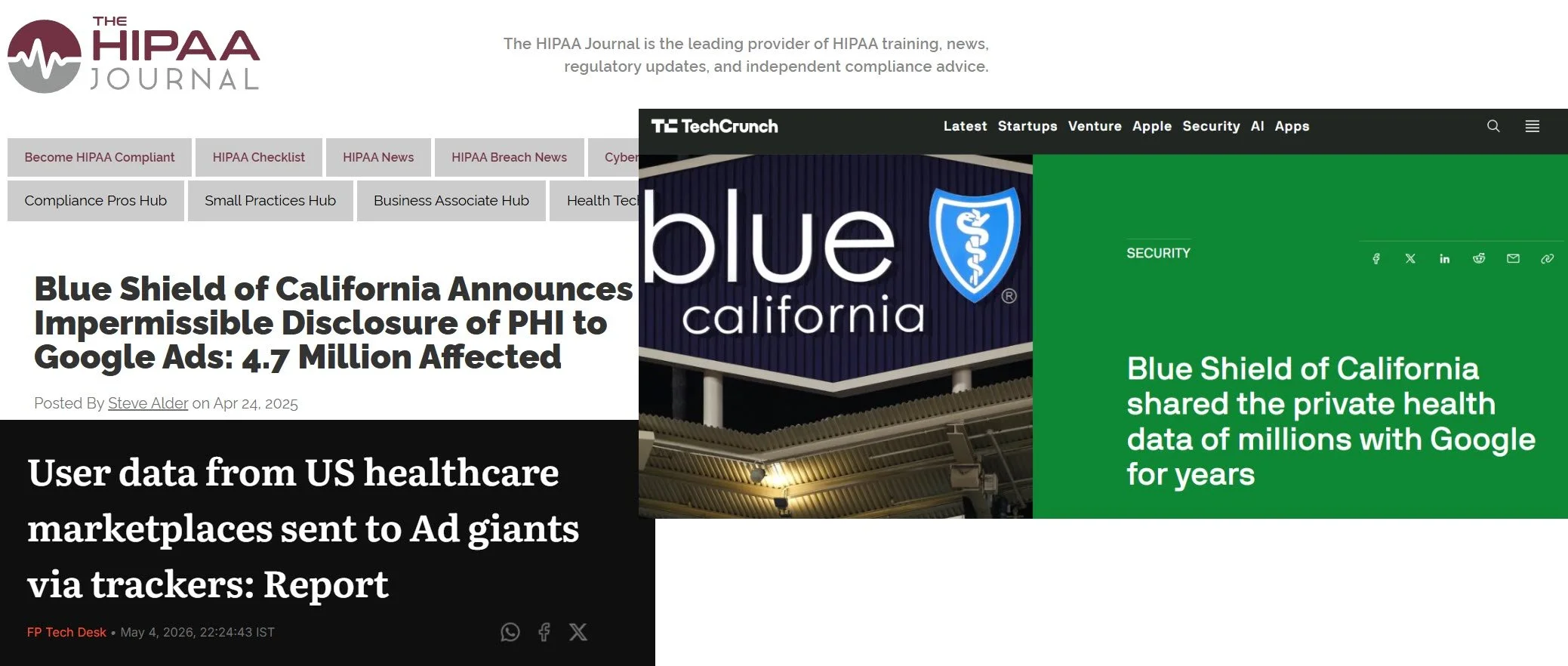
In April 2025, Blue Shield of California disclosed that the private health data of over 4.7 million people had been accidentally shared with Google Ads for three years. HIPAA violation. Massive potential fines. Enormous loss of trust.
Many of us probably aren't running experiments in the healthcare space. But the underlying issue applies across industries. Every time you store individual-level user data (who saw what variation, what they clicked, how long they stayed), you're still creating a liability. And the more you store, the bigger the risk.
(Tangent: The risk is even bigger in the LLM age…and millions of users - including your team members - are uploading your company data right into those LLMs, assuming it’s safe. It’s not. Far from it.)
The traditional fix is better policies. Better governance. More checklists.
Conductrics’ argument is: what if you just... didn't?
The Surprisingly Simple Insight
Here's the core of Gershoff’s paper, stripped of all the matrix notation:
You don't need individual-level data to run a valid A/B test. You only need totals.
That's it. That's the headline. The tl;dr. Or rather, the very long did read, cried some, asked my 21-year-old mathematics major who loves linear algebra to explain, and 3 hours and several whiteboards and lectures later, I finally got…. Why didn’t you just say that, Matt? (You did? Sure, sure.) The point is, it’s not an easy concept to explain - but, once someone who does NOT love math and matrices as much as Matt and Geoff (my math-loving 21-year-old) actually gets to the point of understanding, well, then it becomes easy. Then, you get to:
Aggregate numbers are all the math actually needs. The individual rows? Optional (just a habit, really). And risky.
The privacy framework Conductrics uses to formalize this is called K-anonymity. The idea: group your data so that any single person blends into a crowd of at least K others. An individual can't be singled out because they're indistinguishable from the group they've been aggregated into.
Imagine you’re trying to blend into a crowd. Ever heard the joke about two people finding out they were both at Woodstock? Highly unlikely they met there. Conversely, a local pub in a small town where Willie Nelson played that one time, unexpectedly, with a $5 cover - I guarantee you that everyone who was there that night remembers everyone they met that night. (Trust me - I was there. It was a night to remember.)
"Okay, But What About More Advanced Tests?"
Basic A/B comparison is one thing. But what about all the more sophisticated stuff we care about in this community?
Good news: still holds up.
Running multiple tests at the same time? A common worry is that two simultaneous tests might interfere with each other: the CTA test, for example, might mess with the checkout flow test. Conductrics' method can check for this using something called a partial F-test, which compares a simpler model with a more complex one to determine whether the interference is real or just noise. And it works entirely on the grouped summary data.
Do different customer segments respond differently? Maybe the new feature lands great with new users, but does nothing for power users. These are called conditional treatment effects, and yep, the grouped-data approach can surface these differences, too.
Variance reduction (CUPED / ANCOVA)? The quick version: CUPED uses what you already know about a user before the test starts to reduce background noise and make your results cleaner, meaning you can run shorter tests or use smaller sample sizes and still trust your results. Conductrics implements the equivalent of this (using something called ANCOVAII, developed by statistician Winston Lin) entirely on K-anonymous, grouped data. No individual records required.
The math produces the same results as if you'd run it on individual-level data. Which, honestly, 🤯.
Two Ways to Build It
Conductrics describes two practical approaches for organizations that want to implement this:
The "Never Collect It" approach: the user's device performs the math locally and sends only a summary update to the server. Something like "one more person in Group B, they spent 5 minutes on the app." Individual data never gets centralized. The server only ever sees running totals. This is the most privacy-protective option, and also the most architecturally involved.
The "Collect but Lock It Down" approach: You collect individual data as you normally would, but a designated gatekeeper converts it into grouped summaries before any analyst touches it. Analysts only ever see the privacy-safe totals. This is easier to retrofit onto existing infrastructure and is probably the more realistic starting point for most organizations.
Bonus: Money, Money, Money, Money!
Here's the part that surprised me most, and it comes from the Conductrics blog post that inspired this one.
Netflix (one of the largest A/B testing operations in the world) independently arrived at this same grouped-data approach. Not because of privacy concerns. But because processing millions of individual user records for every experiment is enormously expensive in cloud computing costs.
They got there from a completely different direction and landed in the exact same place.
So Conductrics' privacy-first architecture turns out to also be a performance-first architecture. Better privacy. Lower compute costs. Same statistical power. That's a rare triple win. (Hat trick!)
Why This Matters for Our Community
If you're an experimenter, this is worth understanding because it changes how you think about data collection at the architecture level, not just the analysis level. The question isn't just "how do we analyze this data?" but "how little data do we actually need to collect in the first place?"
If you're managing a team, this is a conversation worth having with your engineering and legal counterparts. The compliance risk of individual-level experimentation data is real, and "we have a policy about that" is not the same as "we have a system that makes the risk structurally impossible."
If you're in a regulated industry (healthcare, finance, insurance), this isn't theoretical. The Blue Shield situation was a real company, real people, real consequences. The architecture Conductrics describes is directly relevant to your context.
And if you're just here to learn, the core insight is beautiful in its simplicity. Most of what we need to know from an A/B test can be learned from counts and sums.
Individual rows of data are a habit, not a requirement.
Go Read the Paper (or at Least Dominika's Post)
The full paper is in Applied Marketing Analytics, Vol. 11, No. 3. Fair warning: there are matrices. Lots and lots of them. Matt is who he is, and we universally adore him for it. Please don’t stop being you, Matt. We’ve all been #mattgershoffed, and we’re smarter for it. Every time.
Dominika's blog post on the Conductrics site is a much gentler on-ramp and worth reading alongside this one.
And if you want to talk through any of this, that's literally what the Test & Learn Community is for. Join the conversation! (already in progress)
Reading
When less is more: Engineering privacy by design into A/B testing, Dominika Gruszkiewicz, Conductrics
Agnostic notes on regression adjustments to experimental data: Reexamining Freedman’s critique, Winston Lin.
Blue Shield of California shared the private health data of millions with Google for years. Zack Whittaker, TechCrunch.
Oddest ChatGPT leaks yet: Cringey chat logs found in Google Analytics tool. Ashley Belanger, ArsTechnica.
ChatGPT Data Leakage: How Employees Accidentally Expose Proprietary Data. CentrexIT Team
Disclosure: Conductrics is a sponsor of the Test & Learn Community. This post reflects my own reading of their research and does not represent a paid or coordinated placement.